
在“”中提到了归纳偏置实际上是一种模型选择策略,尽管我们认为A模型更简单可能具有更好的泛化能力(更贴切实际问题对新数据的预测更准)而选择了A,但是实际情况中很可能会出现B模型比A更好的情况如图所示:(注:本文实际是对周志华西瓜书的部分总结)
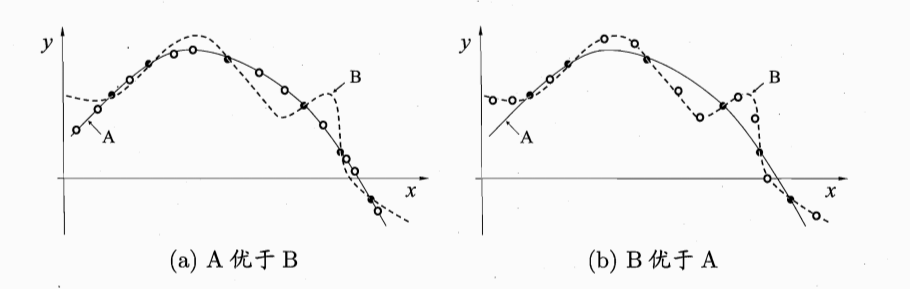
黑点是训练数据,空心点是新数据,在(b)图中B模型比A模型更好。
也就是说在无数个模型中都可能会出现比A模型与实际数据更符合的情况(西瓜书中引入了NFL(没有免费的午餐定理)来着重说明具体问题具体分析,这个具体问题实际上是指数据分布要与实际问题一致而不是指应用场景一致),换句话说哪个模型与实际情况更加符合我们就选择那个模型。
现在的问题是我们如何判断哪个模型与实际情况更加符合,因此引入了模型的评估和选择。
在评估和选择时,虽然使用了N种方法,但本质上还是将数据分成了训练集和测试集分别进行模型训练和模型验证,我们理想中的情况是训练集与测试集要同时与实际数据的概率分布一致,只有这样我们才能通过技术手段尽量选择到那个最优的模型,那N种方法直观上模型评估选择法,本质上是尽量保证与实际数据的概率分布一致!